Services Web
Koha fournit un certain nombre d’API donnant l’accès à ses données et fonctions.
OAI-PMH
Concernant le « Open Archives Initiative-Protocol for Metadata Harvesting » (OAI-PMH) il y a deux groupes de « participants » : les fournisseurs de données, et les fournisseurs de services. Les fournisseurs de données (archives ouvertes, entrepôts numériques) offrent un accès gratuit aux métadonnées, et peuvent parfois offrir un accès gratuit à des articles en plein texte ou à d’autres ressources. OAI-PMH offre une solution facile a intégrer avec peu de barrières pour les fournisseurs de données. Les fournisseurs de services utilisent les interfaces OAI des fournisseurs de données pour moissonner et stocker des métadonnées. Notez que ceci signifie qu’il n’y a pas de recherche dynamique dans auprès des fournisseurs de données; les services sont plutôt basés sur les données moissonnées via OAI-PMH.
Pour en savoir plus sur OAI-PMH : https://www.openarchives.org/pmh/
Koha peut agir à la fois comme un Fournisseur de Données et comme un Fournisseur de Service. Cette section documente son usage comme Fournisseur de Données. Pour les informations sur son usage comme Fournisseur de Service, consultez la section OAI repositories.
Pour activer OAI-PMH dans Koha, modifiez la préférence système OAI-PMH. Une fois que vous l’avez activée, allez sur http://YOURKOHACATALOG/cgi-bin/koha/oai.pl pour voir votre fichier.
Par défaut, Koha n’inclut pas de données de l’exemplaire dans les sets OAI-PMH, mais elles peuvent être ajoutées en utilisant l’option include_items dans le fichier de configuration paramétré dans OAI-PMH:ConfFile.
Notez que l’échantillon de fichier de configuration ci-dessous contient du marc21 et du marcxml, car marc21 est le préfixe de metadata recommandé par les directives de OAI-PMH tandis que marcxml était le seul dans l’échantillon avant la version 23.11 de Koha (et la gestion pour marc21 a été intégrée dès la version 17.05 de Koha).
Échantillon de Fichier de Configuration OAI
format:
vs:
metadataPrefix: vs
metadataNamespace: http://veryspecial.tamil.fr/vs/format-pivot/1.1/vs
schema: http://veryspecial.tamil.fr/vs/format-pivot/1.1/vs.xsd
xsl_file: /usr/local/koha/xslt/vs.xsl
marc21:
metadataPrefix: marc21
metadataNamespace: https://www.loc.gov/MARC21/slim https://www.loc.gov/standards/marcxml/schema/MARC21slim
schema: https://www.loc.gov/MARC21/slim https://www.loc.gov/standards/marcxml/schema/MARC21slim.xsd
include_items: 1
marcxml:
metadataPrefix: marcxml
metadataNamespace: https://www.loc.gov/MARC21/slim https://www.loc.gov/standards/marcxml/schema/MARC21slim
schema: https://www.loc.gov/MARC21/slim https://www.loc.gov/standards/marcxml/schema/MARC21slim.xsd
include_items: 1
oai_dc:
metadataPrefix: oai_dc
metadataNamespace: https://www.openarchives.org/OAI/2.0/oai_dc/
schema: https://www.openarchives.org/OAI/2.0/oai_dc.xsd
xsl_file: /usr/local/koha/koha-tmpl/intranet-tmpl/xslt/UNIMARCslim2OAIDC.xsl
Les options sont :
xsl_file : Chemin vers un fichier XSLT qui sera utilisé pour transformer les données MARCXML dans le format / structure nécessaire. Il peut être utile, par exemple, si vous avez besoin que des champs Dublin Core spécifiques soient générés à la place des quelques champs par défaut.
include_items : S’il est paramétré sur 1, les données exemplaires seront incluses dans la réponse en fonction de la correspondance de la grille MARC.
expanded_avs : S’il est paramétré sur 1, toutes les valeurs codées seront affichées avec leur description. Ceci inclut les noms des bibliothèques, les descriptions des types de document, des valeurs autorisées et des sources de classification.
Toutes ces options peuvent être utilisées avec différentes entrées metadataPrefix, permettant aux clients d’interroger l’une ou l’autre.
Serveur SRU
Koha implémente le protocole de recherche et de récupération via URL (Search/Retrieve via URL - SRU). Vous pouvez trouver plus d’informations à propos du protocole sur https://www.loc.gov/standards/sru/. La version implémentée est la version 1.1.
Explications
Si vous souhaitez avoir plus d’informations à propos de l’implémentation du SRU sur un serveur spécifique, allez sur le fichier Explain en envoyant une requête au serveur sans aucun paramètre. Par exemple http://myserver.com:9999/biblios/. La réponse du serveur est un fichier XML qui devrait ressembler à ce qui suit, et vous donnera des informations concernant les paramètres par défaut du serveur SRU.
<zs:explainResponse>
<zs:version>1.1</zs:version>
<zs:record>
<zs:recordSchema>http://explain.z3950.org/dtd/2.0/</zs:recordSchema>
<zs:recordPacking>xml</zs:recordPacking>
<zs:recordData>
<explain xml:base="zebradb/explain-biblios.xml">
<!--
try stylesheet url: http://./?stylesheet=docpath/sru2.xsl
-->
<serverInfo protocol="SRW/SRU/Z39.50">
<host>biblibre</host>
<port>9999</port>
<database>biblios</database>
</serverInfo>
<databaseInfo>
<title lang="en" primary="true">Koha 3 Bibliographic SRU/SRW/Z39.50 server</title>
<description lang="en" primary="true">Koha 3 Bibliographic Server</description>
<links>
<sru>http://biblibre:9999</sru>
</links>
</databaseInfo>
<indexInfo>
<set name="cql" identifier="info:srw/cql-context-set/1/cql-v1.1">
<title>CQL Standard Set</title>
</set>
<index search="true" scan="true" sort="false">
<title lang="en">CQL Server Choice</title>
<map>
<name set="cql">serverChoice</name>
</map>
<map>
<attr type="1" set="bib1">text</attr>
</map>
</index>
<index search="true" scan="true" sort="false">
<title lang="en">CQL All</title>
<map>
<name set="cql">all</name>
</map>
<map>
<attr type="1" set="bib1">text</attr>
</map>
</index>
<!-- Record ID index -->
<index search="true" scan="true" sort="false">
<title lang="en">Record ID</title>
<map>
<name set="rec">id</name>
</map>
<map>
<attr type="1" set="bib1">rec:id</attr>
<attr type="4" set="bib1">3</attr>
</map>
</index>
Rechercher
Cette URL : http://myserver.com:9999/biblios?version=1.1&operation=searchRetrieve&query=reefs est composé des éléments suivants :
url de la base du serveur SRU : http://myserver.com:9999/biblios?
partie de recherche avec les 3 paramètres requis : version, opération et requête. Les paramètres à l’intérieur de la partie recherche devront être de la forme clé=valeur, et peuvent être combinés avec le caractère &.
Il est possible d’ajouter des paramètres optionnels à la requête, par exemple maximumRecords indique le nombre maximum de notices que le serveur rend. Donc, http://myserver.com:9999/biblios?version=1.1&operation=searchRetrieve&query=reefs&maximumRecords=5 obtiendra seulement les 5 premiers résultats du serveur.
La clé « opération » peut prendre deux valeurs : scan ou searchRetrieve.
Si operation=searchRetrieve, alors la clé de recherche devra être la requête. Comme dans : operation=searchRetrieve&query=reefs
Si operation=scan, alors la clé de recherche devra être scanClause. Comme dans : operation=scan&scanClause=reefs
etc/zebradb/biblios/etc/bib1.att définit les index Zebra/3950 qui existent dans votre système. Par exemple, vous verrez que nous avons des index pour Sujet et pour Titre : respectivement att 21 Subject et att 4 Title.
Dans le fichier pqf.properties localisé sous etc/zebradb/pqf.properties, je peux voir un point d’accès qui utilise déjà mon index Subject (index.dc.subject = 1=21) alors que l’autre utilise mon index Title (index.dc.title = 1=4). Je sais que c’est mon index car je l’ai vu juste avant dans mon fichier bib1.att, il est appelé avec un =1=21 dans Z3950 : donc index.dc.subject = 1=21 correspond correctement à mon index Subject. Le Title est appelé par 1=4 donc index.dc.title = 1=4 correspond à mon index Title. Je peux maintenant construire ma requête comme dans une barre de recherche, en la précédant de la clé « query »: query=Subject=récifs and Title=corail recherche « récifs » dans le sujet et « corail » dans le titre. L’url entière serait http://myserver.com:9999/biblios?version=1.1&operation=searchRetrieve&query=Subject=récifs and Title=corail Si je veux limiter le résultat à 5 notices, je peux faire http://myserver.com:9999/biblios?version=1.1&operation=searchRetrieve&query=Subject=récifs and Title=corail&maximumRecords=5
Je peux aussi le faire avec des troncatures, relations, etc… Elles aussi définies dans mon fichier pqf.properties. Je peux voir par exemple les propriétés de position définies comme :
position.first = 3=1 6=1
# "first in field"
position.any = 3=3 6=1
# "any position in field"
Par exemple, si je veux que « corail » soit au début du titre, je peux faire cette requête : http://myserver.com:9999/biblios?version=1.1&operation=searchRetrieve&query=Title=corail first
Récupérer
Ma recherche pour http://univ_lyon3.biblibre.com:9999/biblios?version=1.1&operation=searchRetrieve&query=coral reefs&maximumRecords=1 récupère seulement une notice. La réponse ressemble à ceci :
<zs:searchRetrieveResponse>
<zs:version>1.1</zs:version>
<zs:numberOfRecords>1</zs:numberOfRecords>
<zs:records>
<zs:record>
<zs:recordPacking>xml</zs:recordPacking>
<zs:recordData>
<record xsi:schemaLocation="http://www.loc.gov/MARC21/slim http://www.loc.gov/ standards/marcxml/schema/MARC21slim.xsd">
<leader> cam a22 4500</leader>
<datafield tag="010" ind1=" " ind2=" ">
<subfield code="a">2-603-01193-6</subfield>
<subfield code="b">rel.</subfield>
<subfield code="d">159 F</subfield>
</datafield>
<datafield tag="020" ind1=" " ind2=" ">
<subfield code="a">FR</subfield>
<subfield code="b">00065351</subfield>
</datafield>
<datafield tag="101" ind1="1" ind2=" ">
<subfield code="c">ita</subfield>
</datafield>
<datafield tag="105" ind1=" " ind2=" ">
<subfield code="a">a z 00|y|</subfield>
</datafield>
<datafield tag="106" ind1=" " ind2=" ">
<subfield code="a">r</subfield>
</datafield>
<datafield tag="100" ind1=" " ind2=" ">
<subfield code="a">20091130 frey50 </subfield>
</datafield>
<datafield tag="200" ind1="1" ind2=" ">
<subfield code="a">Guide des récifs coralliens / A Guide to Coral Reefs</subfield>
<subfield code="b">Texte imprimé</subfield>
<subfield code="e">la faune sous-marine des coraux</subfield>
<subfield code="f">A. et A. Ferrari</subfield>
</datafield>
<datafield tag="210" ind1=" " ind2=" ">
<subfield code="a">Lausanne</subfield>
<subfield code="a">Paris</subfield>
<subfield code="c">Delachaux et Niestlé</subfield>
<subfield code="d">cop. 2000</subfield>
<subfield code="e">impr. en Espagne</subfield>
</datafield>
<datafield tag="215" ind1=" " ind2=" ">
<subfield code="a">287 p.</subfield>
<subfield code="c">ill. en coul., couv. ill. en coul.</subfield>
<subfield code="d">20 cm</subfield>
</datafield>
......
<idzebra>
<size>4725</size>
<localnumber>2</localnumber>
<filename>/tmp/nw10BJv9Pk/upd_biblio/exported_records</filename>
</idzebra>
</record>
</zs:recordData>
<zs:recordPosition>1</zs:recordPosition>
</zs:record>
</zs:records>
</zs:searchRetrieveResponse>
ILS-DI
Au moment où s’écrivent ces lignes, l’ILS-DI auto-documentée est l’interface la plus complète. Après son activation, décrite dans la section Préférences sytème ILS-DI, la documentation devrait être disponible sur https://YOURKOHACATALOG/cgi-bin/koha/ilsdi.pl
Web services JSON
Koha crée un web service JSON pour chaque rapport sauvegardé en utilisant les fonctionnalités Assistant de rapport ou Créer à partir d’une requête SQL.
Par défaut, les rapports ne sont pas publics et sont accessibles seulement aux utilisateurs authentifiés. Si un rapport est clairement paramétré sur public, il sera accessible sans aucune authentification. Cette fonctionnalité devrait n’être utilisée que si les données peuvent être partagées car ne contenant aucune information sur les adhérents.
On peut accéder aux rapports en utilisant les URLs suivantes :
Rapports publics
OpacBaseURL/cgi-bin/koha/svc/report?id=REPORTID
Rapports privés
StaffBaseURL/cgi-bin/koha/svc/report?id=REPORTID
Il existe également des paramètres complémentaires :
Au lieu d’accéder au rapport par son REPORTID, vous pouvez utiliser son nom :
…/cgi-bin/koha/svc/report?name=REPORTNAME
Pour faciliter le développement, il existe également une option permettant de générer une sortie des données annotée. Cette option génère une table de hachage dont les clés sont les noms des champs.
…/cgi-bin/koha/svc/report?name=REPORTNAME&annotated=1
Effort de versionnage des API RESTful
Il y a un effort continu pour faire converger les APIs ci-dessus en un seul ensemble versionné de points de terminaisons RESTful modernes documentés à l’aide du standard OpenAPI et disponibles par défaut sous https://YOURKOHACATALOG/api/v1/
La documentation complète pour les API de votre version peut se trouver à api.koha-community.org.
Octroi du certificat du client OAuth2
Koha prend en charge l’authentification client OAuth2 comme moyen de sécuriser l’API pour l’utiliser à partir d’autres systèmes afin de respecter les normes actuelles de l’industrie. De plus amples renseignements sur la norme OAuth2 relatifs à l’octroi d’une autorisation clients se trouvent ici : <https://auth0.com/docs/get-started/authentication-and-authorization-flow/client-credentials-flow>`_.
Inteface de gestion de clé API pour les adhérents
Afin que les clés API soient créées pour les adhérents, la préférence système RESTOAuth2ClientCredentials doit être activée pour que l’option apparaisse dans la notice d’un adhérent.
Choisissez le dossier d’un adhérent et sélectionnez Plus > Gestion des clés API
Si aucune clé API n’existe pour un adhérent, un message s’affichera pour générer un ensemble identifiant / secret

Entrer une description pour la paire ID client/secret et cliquer sur Enregistrer
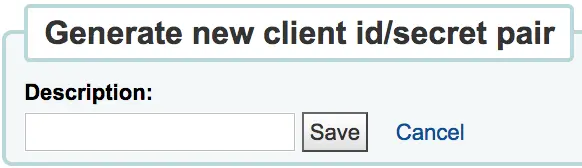
Koha va générer une paire ID client/secret pour se connecter à Koha depuis un système tiers comme un utilisateur authentifié

Cliquer sur le bouton Révoquer à côté d’une paire d’un identifiant API rendra cette paire d’identifiants inactive jusqu’à sa réactivation
Générateur d’image de code à barres
Koha propose un générateur d’image de code à barres sur les interfaces professionnelles et publiques. Chacune d’entre elles nécessite de s’identifier, pour éviter tout abus d’un tiers.
Par exemple :
/cgi-bin/koha/svc/barcode?barcode=123456789&type=UPCE
L’URL ci-dessus va générer l’image d’un code à barres « 123456789 », en utilisant le format de code à barres UPCE.
Les différents types de code à barres disponibles sont : * Code39 * UPCE * UPCA * QRcode * NW7 * Matrix2of5 * ITF * Industrial2of5 * IATA2of5 * EAN8 * EAN13 * COOP2of5
Si aucun type n’est spécifié, Code39 sera utilisé.
Par défaut, l’image du code à barres contiendra aussi le texte du code à barres. Si ça n’est pas souhaité, le paramètre « notext » peut être utilisé pour éviter cela.
Par exemple :
/cgi-bin/koha/svc/barcode?barcode=123456789¬ext=1
génèrera l’image d’un code à barres 123456789 sans le texte « 123456789 » dessous.
Ce service peut être utilisé pour incorporer des images de codes à barres dans les tickets et notifications imprimés à partir du navigateur, ou incorporer le numéro de carte d’un adhérent à l’OPAC, entre autres choses.