Domande frequenti
Installazione
Domanda: Come posso sapere qual è la versione di Koha che sto usando?
Answer: The easiest way to find out your Koha version is taking a look at the About page of the staff interface.
Puoi anche capirlo dall’OPAC guardando nel codice HTML. Vedrai qualcosa di simile:
<meta name="generator" content="Koha 23.1100000" /> <!-- leave this for stats -->
Domanda: per installare Koha, devo usare i package Debian o il tarball?
Answer: It is highly recommended that you use packages to install Koha. It is the easiest way to install Koha, and provides many commands to help manage your Koha installation.
Use the Koha on Debian and Ubuntu instructions [https://wiki.koha-community.org/wiki/Koha_on_Debian_and_Ubuntu] on the Wiki to install Koha on Debian-based systems (including Debian, Ubuntu, and Mint).
The package commands [https://wiki.koha-community.org/wiki/Commands_provided_by_the_Debian_packages] page on the Wiki has an introduction and basic information about the commands available.
Only install Koha using the tarball or git if you have a specific need (such as installing Koha on non-Debian-based systems) and are an experienced GNU/Linux system administrator.
Developers should use KTD (koha-testing-docker) [https://gitlab.com/koha-community/koha-testing-docker] , as it’s the easiest and quickest way to get a development environment running.
OPAC e interfaccia staff
Personalizzare le immagini di Koha
Domanda: E” possibile personalizzare le immagini nell’OPAC?
Rsiposta:: Certamente. Koha è fornito con una serie di immagini originali, che si possono modificare per adattarle alle proprie esigenze. Gli originali si trovano nella cartella misc/interface_customization/.
Visualizzazione dei campi nell’OPAC
Domanda:: Quali campi MARC appaiono nelle diverse videate dell’OPAC in Koha?
Risposta: La preferenza XSLT deve essere impostata come di seguito indicato, per far apparire i campi seguenti
OPACXSLTResultsDisplay = using XSLT stylesheets
OPACXSLTDetailsDisplay = using XSLT stylesheets
DisplayOPACiconsXSLT = show
La pagina Risultati nell’OPAC visualizza i campi:
245
100, 110, 111
700, 710, 711
250
260
246
856
La pagina Dettagli dell’OPAC visualizza i campi:
245
100, 110, 111
700, 710, 711
440, 490
260
250
300
020
022
246
130, 240
6xx
856
505
Campo 773
520
866
775
780
785
oltre a tutti i campi 5xx nella scheda Note al fondo
Mostrare agli utenti i codici a barre degli elementi che hanno chiesto in prestito
Domanda: Gli utenti possono visualizzare i codici a barre degli elementi che hanno in prestito?
Answer: Not by default, but with a few edits to the patron record you can make a barcode column appear on the patron’s check out summary in the OPAC. You can set up a patron attribute with the value of SHOW_BCODE and authorized value of YES_NO to make this happen.
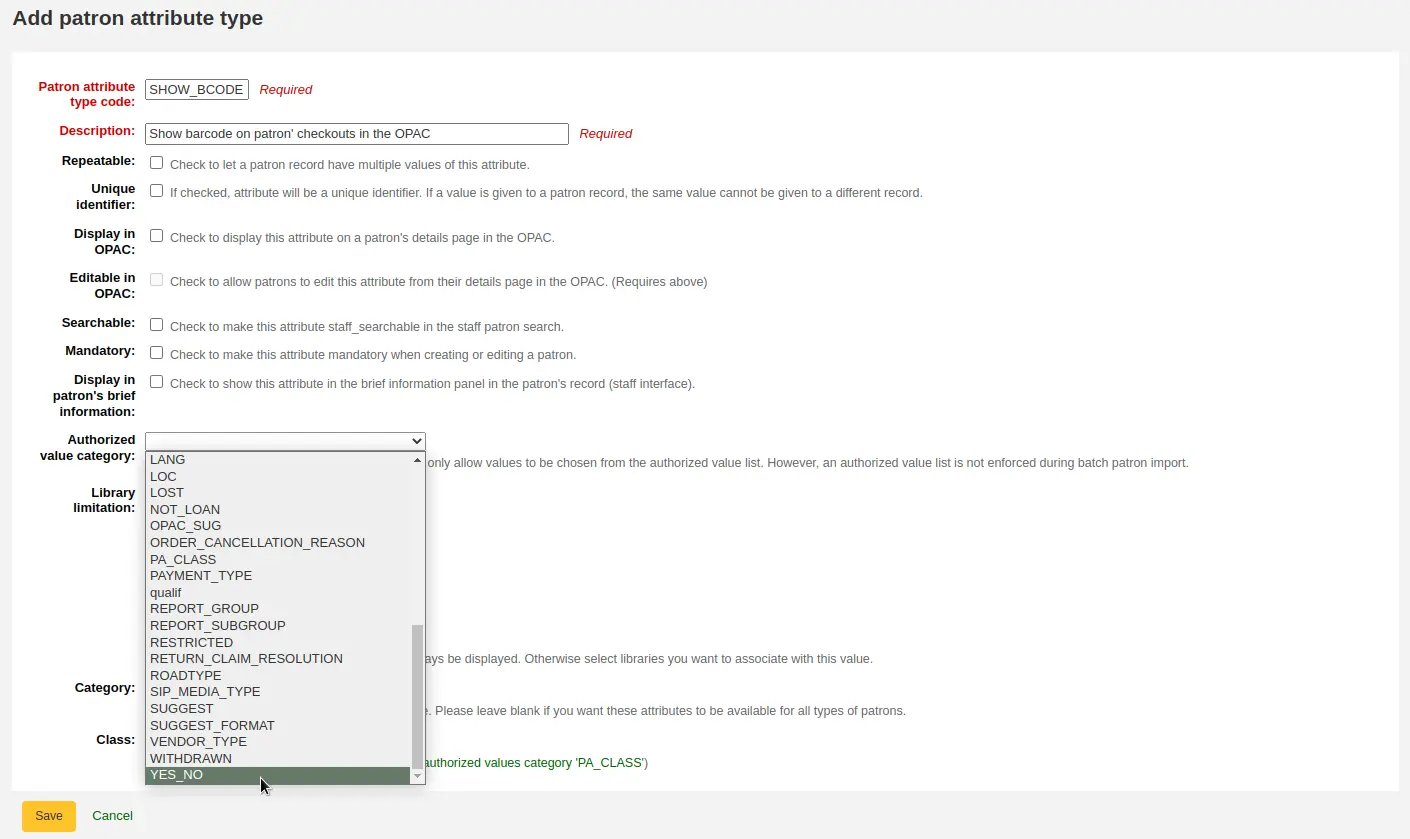
Poi modifica l’utente e poni il campo SHOW_BCODE a “yes”.
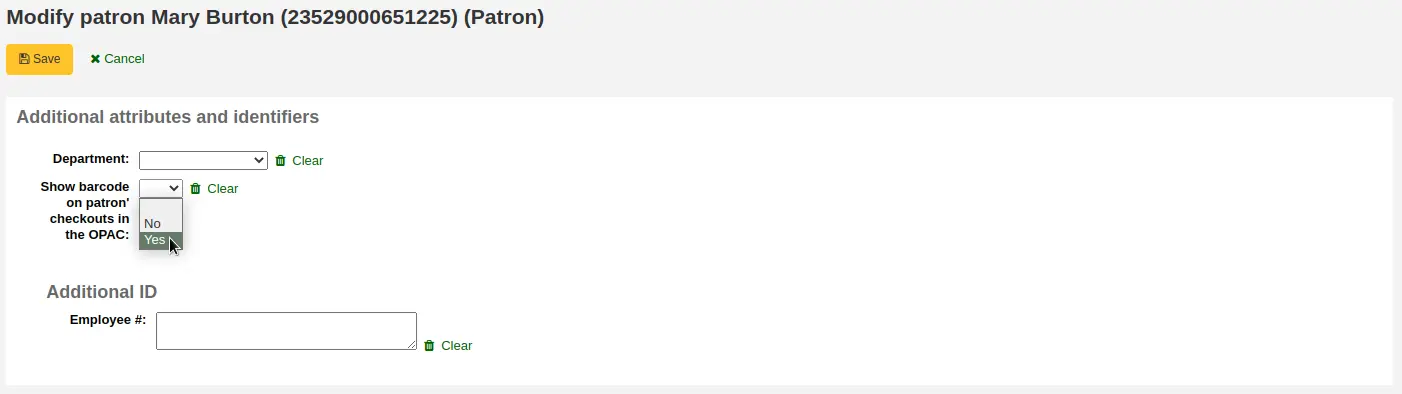
Verrà aggiunta una colonna nella sintesi dei prestiti nell’OPAC che mostra agli utenti il codici a barre delle copie in prestito.
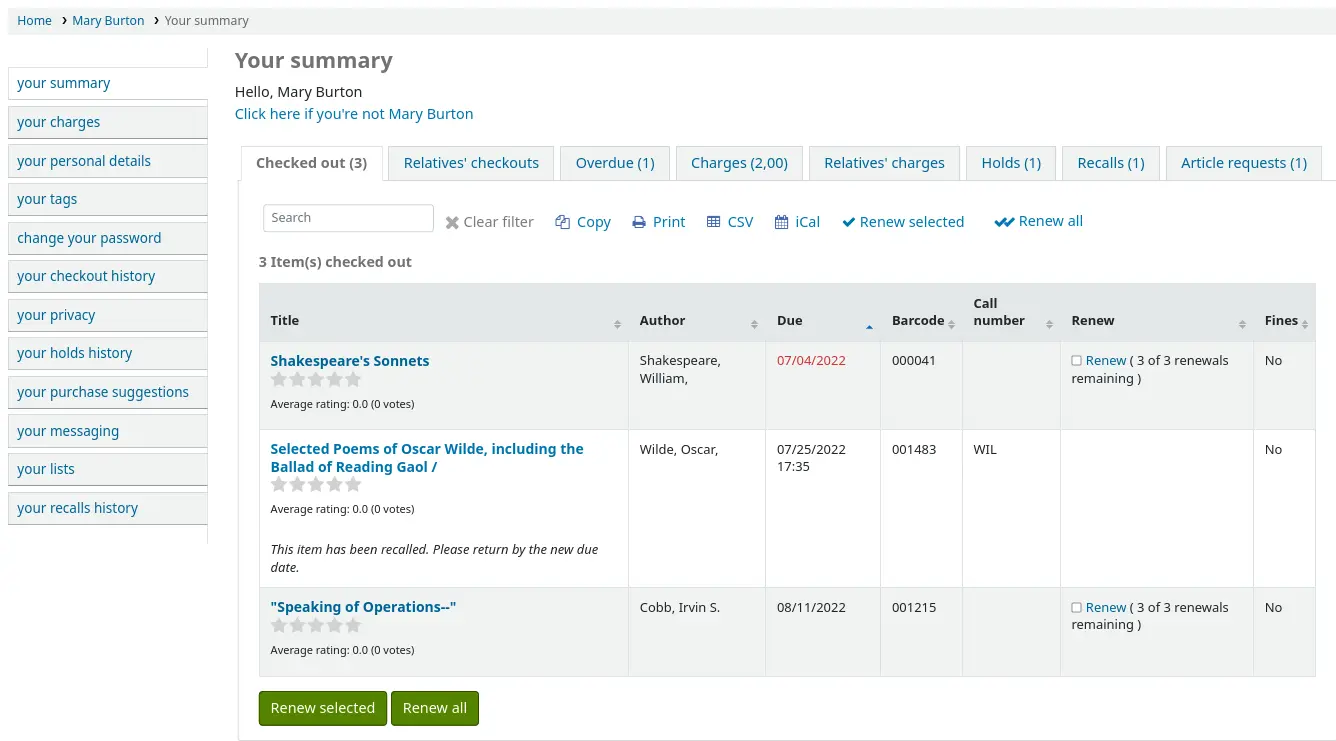
Facendo clic sulla scheda “in ritardo” verranno mostrate solo le copie prestate in ritardo di restituzione.
Circulation/notices
Multe e tariffe
Domanda: Perché devo pagare 5,00 per ogni prestito?
Answer: The money you are seeing on your patron’s account isn’t a fine, but a rental fee. The optional default item types that come with the Koha sample data might contain a rental fee. To remove this fee, do the following:
Clicca su Più > Amministrazione del sistema
Clicca su Tipi di copia
Vedi i tipi di copia che hanno un 5.00 associato e selezionali per la modifica
Rimuovi la tassa e salva il tipo di copia
Cassetta di riconsegna
Domanda: Come viene determinata la data di deposito nella cassetta di riconsegna? E” l’ultimo giorno utile di apertura della filiale? E” la data di oggi meno un giorno? Si può impostare la data di deposito nella cassetta di riconsegna?
Risposta: Se la biblioteca è chiusa per quattro giorni (per ristrutturazioni, per esempio), sarebbe necessario più di un giorno per stabilire la data di deposito nella cassetta di riconsegna. Esiste una sola data di riconsegna, ed è l’ultimo giorno utile di apertura della biblioteca (come stabilito dal calendario delle festività), perché non c’è modo di sapere quando il libro è stato depositato nella cassetta di riconsegna, durante i quattro giorni di chiusura. L’unico modo di cambiare la data di restituzione effettiva, in modalità «dropbox», è di modificare il calendario.
If you need to set a different checkin date, you can use the SpecifyReturnDate system preference. This will allow you to set an arbitrary date and any overdue fines will be recalculated accordingly.
Prenotazioni da trattare e Prenotazioni in coda
Domanda: Qual è la differenza tra Prenotazioni in coda e Prenotazioni da trattare?
Risposta: Il prospetto Prenotazioni da trattare produce un semplice elenco di tutte le prenotazioni che devono essere evase, assegnando gli elementi disponibili. E” meglio usarlo solo nelle installazioni di Koha in cui è definita una sola biblioteca.
Il report della coda delle prenotazioni è diviso per biblioteche filiali e listerà la prenotazione solo per una biblioteca dove è disponibile. Per biblioteche con tante prenotazioni ciò impedirà a più biblioteche di prendere la copia dallo scaffale allo stesso tempo.
Il report della coda delle prenotazioni è generato dal cronjob build_holds_queue.pl. Gira per default ogni ora, ma l’intervallo può essere cambiato. Ci sono diverse opzioni di configurazione per determinare quale biblioteca deve fornire la copia prenotata. Per esempio:
Stampa degli avvisi di scadenza
Domanda: Si possono stampare gli avvisi di scadenza per gli utenti che non hanno un indirizzo e-mail?
Risposta: Sì, per default Koha invia alla biblioteca gli avvisi di scadenza degli utenti che non hanno un indirizzo e-mail.
Additionally the overdue notice cron job has a setting to generate the overdue notices as HTML for printing. An example of this usage would be:
- ::
overdue_notices.pl -t -html /tmp/noticedir -itemscontent issuedate,date_due,title,barcode,author
Nell’esempio si sono voluti utilizzare, per produrre gli avvisi, solo alcuni campi della tabella Items, così sulla riga di comando è stata specificata l’opzione itemcontents, seguita dalla lista di campi; non si tratta però di un requisito per utilizzare la funzione.
The command line needs to specify a web-accessible directory where the print notices will go – they get a filename like notices-2018-11-24.html (or holdnotices-2018-11-24.html). The overdue notice itself can be formatted to fit a Z-mailer. Within the notice file, the text is spaced down or over to where it will print properly on the form. The script has code that wraps around the notice file to tell the HTML to obey the formatting, and to do a page break between notices. The system preference PrintNoticesMaxLines can be used to specify the page length for libraries that allow a lot of checkouts which can lead to some notices running onto multiple pages. That system preference says to truncate the print notice at that page length and put in a message about go check your OPAC account for the full list.
The cron entry is gather_print_notices.pl /tmp/noticedir
Impossibile rinnovare i prestiti
Domanda: So provando a rinnovare alcuni prestiti per un nostro utente. Un elemento è prenotato, perciò non il rinnovo non è ammesso, ma per altri due il sistema rifiuta il rinnovo, anche se dovrebbe essere consentito. Se provo ad utilizzare la funzione Forza limite di rinnovo, questa restituisce solo il messaggio «Rinnovo fallito». Che cosa sta succedendo?
Answer: At the very least you will need to set an absolute default circulation rule. This rule should be as standard rule for all libraries, “All” itemtype”, and “All” patron category. That will catch anyone who doesn’t match a specific rule. Patrons who do not match a specific rule will get blocked from placing holds or renewing items, since there was no baseline number of holds or renewals to utilize.
Impossibile prenotare
Domanda: Perché non a fare prenotazioni quando ho attivato tutte le preferenze?
Risposta: Probabilmente è necessario impostare una regola di circolazione predefinita, vedi Regole di circolazione e multe. Come minimo assoluto, si deve impostare una regola di circolazione predefinita generale. Questa regola dev’essere impostata per tutti i tipi di elemento tutte le biblioteche e tutte le categorie di utenti. In questo modo, tale regola si applicherà a chiunque non ricada in un’altra regola specifica. Quando si fa un prestito, se non c’è una regola per la biblioteca predefinita, l’elemento predefinito e la categoria di utenti predefinita, può accadere che gli utenti non riescano a fare le prenotazioni.
La possibilità di fare prenotazioni dipende anche dall’impostazione di “Prenotazioni a scaffale consentite” nella relativa regola di circolazione. In funzione dell’impostazione, potrebbe non essere possibile fare prenotazioni, a meno che una copia o tutte del record siano in prestito.
Scorciatoie da tastiera
Domanda: Bisogna usare il mouse per accedere alle linguette Prestito, Restituzione e Catalogazione nella parte alta delle pagine di circolazione?
Risposta: Si può passare da una linguetta all’altra, nel box di ricerca situato nella parte alta dello schermo, con le seguenti combinazioni di tasti (se la linguetta è abilitata):
vai alla ricerca con alt+Q
vai al prestito con Alt+U
questo non funziona per utenti Mac
vai ai rinnovi con alt+W
vai alla restituzione prestiti con alt+R
Nota
Gli utenti Mac devono usare il bottone OPTION al posto di ALT
Avvisi e messaggi via SMS
Domanda: Vorrei che Koha mandasse gli avvisi via SMS; che cosa devo fare?
Answer: First you need to choose a SMS service to use with Koha. There is a list available at https://metacpan.org/search?q=sms%3A%3Asend Not all SMS services available to libraries have Perl drivers, so be sure to check this list to see if the provider you’re considering is listed. If not you want to ask your provider if they have a Perl module, if not you should consider another service.
Alternatively you can configure Koha to send SMS via Email. In order to use this feature you need to set the SMSSendDriver system preference to “Email” and configure the email gateways for the different SMS cellular providers of your patrons. Be aware that many mobile providers have deprecated support for the SMS::Send::Email feature. It is not recommended for use unless you have a dedicated SMS to Email gateway.
Verifica prima se è legale nel tuo ambito inviare SMS agli utenti.
Domanda: E in India?
Answer: India does not yet have too many options here. This is partly due to the Telecom regulatory authority’s (TRAI) stipulations about transactional SMSes and limits on the number of SMSes that may be sent/received per users per day.
Avvisi e messaggi via email
Domanda: Come posso evitare che gli avvisi della mia biblioteca finiscano nello spam degli utenti?
Risposta: È questione complicata, ma per fortuna Koha offre un buon grado di controllo tramite alcune preferenze di sistema.
Per ogni email spedito da Koha, ci sono indirizzi importanti da impostare bene: From, Reply-to e Sender. Sono configurabili a livello di sistema e di singola biblioteca e hanno adeguati default.
KohaAdminEmailAddress - Sarà il From e dovrebbe essere un indirizzo nello stesso dominio del server Koha [per esempio noreply@koha-hosting.org]
ReplytoDefault - Agirà da indirizzo Reply-to e può essere di qualunque dominio [per esempio librarian@mylibrary.com] e sarà l’indirizzo usato se e quando l’utente invia un “Reply”, cioè risponde al messaggio. Nota: il default è KohaAdminEmailAddress.
ReturnpathDefault - Questo sarà l’indirizzo del Sender e deve appartenere al dominio di Koha [per esempio postmaster@koha-hosting.org] e sarà l’indirizzo che riceverà indietro messaggi “di rimbalzo”, quelli impossibili da inoltrare..
There are parallels to all the above preferences at the per branch level which fall back in the same order as mentioned above before falling back to the system level preferences above when required.
Se hai configurato tutto come indicato, ma alcuni messaggi sono considerati ancora spam, dovrai sentire il tuo fornitore di servizi email o DNS e fare controllare i record MX, SPF e DKIM.
Catalogazione
Autorità
Question: Why can’t I edit 1xx, 6xx, or 7xx fields in my bibliographic record?

Answer: These fields are authority controlled and you probably have the RequireChoosingExistingAuthority system preference set to «require». When it is set to «require», these fields will be locked and require you to search for an existing authority record to populate the field with. To allow typing in these authority fields set RequireChoosingExistingAuthority to «don’t require».
Domanda: Posso usare Koha senza creare record di autorità?
Risposta: Se non vuoi creare nessun record di autorità, puoi rimuovere il link lasciando in bianco l’impostazione Thesaurus per i campi nelle tue griglie di catalogazione. Vedi anche: Edit dei sottocampi nelle griglie di catalogazione
You can also set the RequireChoosingExistingAuthority system preference to «don’t require» and the AutoCreateAuthorities system preference to «don’t generate». This will allow you to enter anything in controlled fields, and no authority will be created.
Link tra Koha e MARC
Domanda: Qual è la relazione tra «Link tra Koha e MARC» e «Griglia di catalogazione bibliografica MARC»?
Risposta: La corrispondenza tra Koha e MARC si può definire con l’espressione «Griglia di catalogazione bibliografica MARC» OR «Link tra Koha e MARC». «Link tra Koha e MARC» è semplicemente una scorciatoia per velocizzare l’impostazione delle corrispondenze. Se si cambia una mappatura in uno dei due moduli, i cambiamenti si rifletteranno nell’altro automaticamente. In altre parole, ciascun modulo «sovrascrive» i cambiamenti dell’altro, per evitare conflitti.
Numero di copie per record bibliografico
Domanda: C’è un limite al numero di copie che si possono associare ad un record bibliografico?
Answer: There is no limit to the number of items you can attach to a bibliographic record. For records with a big number of items exporting the MARC record as ISO 2709 might be problematic as this format has a size limit. Item numbers somewhere between 600 and 1000 items on a “normal” bibliographic record should be OK.
Analitici
Question: I am using the EasyAnalyticalRecords feature, but my links in the OPAC and Staff client to “Show analytics” are not working.
Answer: If you plan on using EasyAnalyticalRecords you will want to make sure to set your UseControlNumber preference to «Don’t use,» this will prevent broken links.
Acquisizioni
Pianifica categorie
Domanda: Cosa è una categoria con cui si pianifica ?
Risposta: Quando si pianifica in anticipo il modo in cui spendere il proprio budget, innanzitutto si pianifica quanto spendere nel corso del tempo; è la cosa più naturale.
Così si stabilisce di spendere 1000€ a gennaio, 1000€ a febbraio, 3000€ a marzo, ecc. In pratica, si può fare la stessa cosa, utilizzando però una lista di valori al posto dei mesi.
Poniamo di avere di una lista come questa:
< 1 mese
< 6 mesi
< 1 anno
< 3 anni
< 10 anni
> 10 anni
La lista indica quando furono pubblicati i libri da acquistare. Così si costruisce un piano dicendo: voglio spendere almeno il 40% del budget per acquistare libri pubblicati meno di un anno fa, il 10% su libri pubblicati da più di 10 anni, ecc.
Al momento dell’acquisizione di nuovo materiale, sarà possibile, per un dato elemento, scegliere un valore dall’elenco a discesa. Dopo di che, quando il materiale sarà stato acquisito - alla fine dell’anno -, sarà possibile comparare gli obiettivi impostati con quelli che sono stati raggiunti.
Risorse in continuazione
Schemi avanzati
Domanda: Che cos’è il «contatore interno» nell’interfaccia «schemi avanzati» dei periodici?
Risposta: Per meglio comprendere questo punto è opportuno fare un esempio:
Esempio per un abbonamento mensile:
Data di pubblicazione della prima uscita: aprile 2010
Numerazione: N. {X}, anno {Y}
Pirma uscita: N. 4, anno 2010
Per l’anno Y si vuole che l’anno cambi a gennaio 2011
Il modello avanzato per Y sarà:
Agiungi: 1
Ogni: 12
Quando più di: 9999999
Contatore interno: 3
Torna a: 0
Comincia con: 2010
L’anno cambierà dopo aver ricevuto dodici uscite a partire da aprile 2010, cioè ad aprile 2011, se non si imposta il contatore interno. Mettendo il contatore interno a 3, si dice a Koha: cambia l’anno dopo aver ricevuto 12-3 = 9 uscite.
Il contatore interno dice a Koha di tener conto delle prime uscite dell’anno, anche se non sono state ricevute con Koha. Se si inizia l’abbonamento con la prima uscita dell’anno, si lascia in bianco o si mette 0 (zero).
Reports
Aiuto SQL
Domanda: Non conosco il linguaggio SQL, ma vorrei scrivere un report che faccia X. Come posso fare?
Risposta: La reports library di Koha [https://wiki.koha-community.org/wiki/SQL_Reports_Library] nel wiki di Koha è un ottimo punto di partenza dove trovi molti report SQL condivisi da altre biblioteche, che potrai copiare ed adattare per te.
Koha’s database structure [https://schema.koha-community.org] is also publicly documented and contains helpful notes on how the columns in the various tables are used.
Se ti serve aiuto, troverai colleghi a cui rivolgerti nella mailing list di Koha.
Codice contenuto nel database
Tabella Statistics
Domanda: Quali sono i possibili codici per il campo “type” nella tabella “statistics” ?
Risposta:
localuse
Registra se una copia prestata a un utente con finalità statistiche (tipologia utente = “X”) e” rientrata.
issue
return
renew
writeoff
payment
CreditXXX
XXX è un segnaposto per differenti tipi di tariffa, perciò una query che li includa tutti comprende una clausola LIKE, così: «type LIKE “Credit%”»
Circulation rules table
Question: What are the possible codes for the rule_names in the circulation_rules table ?
Risposta:
article_requests = determines whether or not article requests are allowed
auto_renew = determines whether or not checkouts renew automatically
cap_fine_to_replacement_price = determines whether or not the overdue fine is capped at the item’s replacement price
chargeperiod = sets the fine charging interval
chargeperiod_charge_at = determines when in the interval the fine is charge
fine = sets the fine amount
finedays = sets the number of days for a suspension
firstremind = sets the grace period
hardduedate = sets the date in a hard due date
hardduedatecompare = sets the comparison for a hard due date
hold_fulfillment_policy = records the value for «Hold pickup library match» at either the default or itemtype levels
holdallowed = records the value for «Hold policy» at either the default or itemtype levels
holds_per_day = sets the number of holds allowed per day
holds_per_record = ets the number of holds allowed per record
issuelength = sets the loan period
lengthunit = records the unit in which the loan, fine, and suspension intervals are measured
max_holds = records the value for «Total holds allowed» at either the default or category levels
maxissueqty = sets «Current checkouts allowed» for a specific rule
maxonsiteissueqty = sets «Current on-site checkouts allowed» for a specific rule
maxsuspensiondays = sets the maximum number of suspension days
no_auto_renewal_after = sets the number of days after which an automatic renewal is prevented
no_auto_renewal_after_hard_limit = sets the date for a hard limit for automatic renewal
norenewalbefore = sets the number of days before the due date in which to allow renewal
note = records a note about this circulation rule
onshelfholds = determines whether or not on-shelf holds are allowed
opacitemholds = determines whether or not item-level holds are allowed via the OPAC
overduefinescap = sets the amount at which to cap overdue fines
patron_maxissueqty = records the value for «Total current checkouts allowed» at either the default or category levels
patron_maxonsiteissueqty =records the value for «Total current on-site checkouts allowed» at either the default or category levels
refund = records the value for «lost item fee refund on return policy»
renewalperiod = sets the length of a renewal
renewalsallowed = sets the number of renewals allowed
rentaldiscount = sets the rental discount
reservesallowed = sets «Holds allowed (total)» for a specific rule
returnbranch = records the value for «Return policy» at either the default or itemtype levels
suspension_chargeperiod = sets the suspension interval
Reserves (holds) table
Domanda: Quali sono i possibili codici per il campo «found» nelle tabelle «reverses» e «old_reverses» ?
Risposta:
NULL: significa che l’utente ha richiesto la prima copia disponibile e non l’ha scelta
T = Transito: la prenotazione è collegata a una copia che però e in transito nella biblioteca in cui si trova prima di tornare alla bibliotcea che la possiede
W = In attesa: la prenotazione è collegata a una copia che si trova nella biblioteca da cui deve essere ritirata. La copia sta aspettando sullo scaffale che l’utente la venga a ritirare
F = Finished: the hold has been completed, and is done
Tabella Reports Dictionary
Domanda: Quali sono i possibili codici per l’area field in the reports_dictionary table?
Risposta:
1 = Circolazione
2 = Catalogo
3 = Utenti
4 = Acquisizioni
5 = Accounts
Tabella Messages
Domanda: Quali sono i possibili codici per il campo message_type nella tabella messages?
Risposta:
L = Per i bibliotecari
B = per gli utenti
Tabella Serial
Domanda: Quali sono i possibili codici per il campo status nella tabella «serial»?
Risposta:
1 = Atteso
2 = Arrivato
3 = In ritardo
4 = Mancante
5 = Non disponibile
6 = Cancellato
7 = Sollecitato
8 = Fermato
21 = Circulating
22 = Out for binding
23 = Bound
41 = Mancante (non ricevuto)
42 = Mancante (esaurito)
43 = Mancante (danneggiato)
44 = Mancante (smarrito)
Tabella Borrowers
Domanda: Quali sono i possibili codici per la colonna privacy nelle tabelle borrowers e deleted_borrowers?
Risposta:
0 = Sempre
1 = Predefinito
2 = Mai
Tabella categorie utente
Domanda: Quali sono i possibili codici per tipi categorie?
Risposta:
A = Adulto
C = Ragazzo
I = Ente
P = Professionista
S = Staff
X = Statistiche
Tabella Messaging Preferences
Domanda: Quali sono i possibili codici per il campo message_attribute_id nella tabella borrower_message_preferences?
Risposta:
2 = advance notice
6 = prestito
4 = prenotazione completa
1 = scadenza
5 =restituzione
Recalls table
Question: What are the possible codes for the status field in the recalls table?
Risposta:
requested
A new recall request has been made and the item must be returned
waiting
A recalled item is awaiting pickup at the requester’s chosen branch
in_transit
An item has been allocated to a recall and is in transit to the requester’s chosen pickup branch
overdue
A recalled item is overdue to be returned
fulfilled
A recalled item has been checked out to the recall requester, and the recall is complete
expired
The recall was not completed before a defined expiration date or the recall requester failed to pick up their waiting recall within the pickup period
cancelled
The recall request was canceled.
Only requested or overdue recalls can be canceled.
Action logs modules and actions
Question: What are the possible modules in the action_logs table and what are the possible actions for each?
Risposta:
ACQUISITIONS
Records changes to orders and baskets in acquisitions as well as budget adminitration
Possible actions
ADD_BASKET: a new basket was created
APPROVE_BASKET: an EDI basket was approved
CANCEL_ORDER: an order was canceled
CLOSE_BASKET: a basket was closed
CREATE_FUND: a fund was created
CREATE_INVOICE_ADJUSTMENT: an adjustment was added to an invoice
CREATE_ORDER: an order was added to a basket
DELETE_FUND: a fund was deleted
DELETE_INVOICE_ADJUSTMENT: an adjustment was deleted from an invoice
MODIFY_BASKET: a basket was edited (adding or modifying orders)
MODIFY_BASKET_HEADER: a basket’s information (such as the basket name or billing place) was edited
MODIFY_BASKET_USERS: a basket’s users were edited
MODIFY_BUDGET: a budget was edited (this does not include clo)
MODIFY_FUND: a fund was edited
MODIFY_ORDER: an order was edited
RECEIVE_ORDER: an order was received
REOPEN_BASKET: a closed basket was reopened
UPDATE_INVOICE_ADJUSTMENT: an adjustment to an invoice was edited
Enabled by the AcquisitionLog system preference
AUTH
Records when patrons or staff log in to the OPAC or the staff interface
Possible actions
FAILURE: a patron or staff member tried to log in with the wrong credentials
SUCCESS: a patron or staff member logged in successfully
Enabled by the AuthFailureLog and AuthSuccessLog system preferences
AUTHORITIES
Records changes to authority records
Possible actions
ADD: authority record was created
DELETE: authority record was deleted
MODIFY: authority record was modified
Enabled by the AuthoritiesLog system preference
CATALOGUING
Records changes to bibliographic records and items
Possible actions
ADD: bibliographic record or item was created
DELETE: bibliographic record or item was deleted
MODIFY: bibliographic record or item was modified, or a cover image was added to the record
Enabled by the CataloguingLog system preference
CIRCULATION
Possible actions
ISSUE: an item was checked out
RETURN: an item was checked in
RENEWAL: a checkout was renewed
Enabled by the IssueLog, RenewalLog, and ReturnLog system preferences
CLAIMS
Records when late orders are claimed
Possible actions
ACQUISITION CLAIM: a late order was claimed
Enabled by the ClaimsLog system preference
CRONJOBS
Records when a cronjob is run
Possible actions
Run: a cron job was executed
FINES
Records changes to charges
Possible actions
CREATE: a charge was added to a patron’s account (manually or automatically)
MODIFY: a charge was modified (forgiven)
UPDATE: a charge was updated (only in the case of fines that are still accruing)
VOID: a payment was voided
Enabled by the FinesLog system preference
HOLDS
Records changes to holds
Possible actions
CANCEL: a hold was canceled
CREATE: a hold was placed
DELETE: a hold was deleted, an item on hold was checked out by the patron
FILL: a hold was confirmed and put aside to await pickup
MODIFY: a hold was modified (the priority was changed, the expiration date changed, etc.)
RESUME: a suspended hold was resumed
SUSPEND: a hold was suspended
Enabled by the HoldsLog system preference
ILL
Records changes to ILL request.
Possible actions
PATRON_NOTICE: a notice was sent to a patron regarding their ILL request
STATUS_CHANGE: the status of an ILL request was modified
Enabled by the IllLog system preference.
MEMBERS
Records changes to the patron files
Possible actions
ADDCIRCMESSAGE: an internal message or OPAC message was added to the patron’s account
CHANGE PASS: a patron’s password was changed
CREATE: a new patron was added
DELCIRCMESSAGE: an internal message or OPAC message was deleted
DELETE: a patron’s account was deleted
MODIFY: a patron’s account was edited
RENEW: a patron’s membership was renewed
Enabled by the BorrowersLog system preference
NEWS
Records changes to news, HTML customizations, and page.
Possible actions
ADD: a new news item or HTML customization was created
DELETE: a news item or HTML customization was deleted
MODIFY: a news item or HTML customization was edited
Enabled by the AdditionalContentsLog system preference.
NOTICES
Records changes to notice and slips templates.
Possible actions
CREATE: a new notice or slip template was created
DELETE: a notice or slip template was deleted
MODIFY: a notice or slip template was edited
Enabled by the NoticesLog system preference.
RECALLS
Records changes to recalls
Possible actions
CANCEL: a recall was canceled
EXPIRE: a recall expired
FILL: a recall was filled (confirmed and set aside to wait for pickup)
OVERDUE: the status of a recall was set to “overdue”
Enabled by the RecallsLog system preference
REPORTS
Records changes to reports
Possible actions
ADD: a new report was created
DELETE: a report was deleted
MODIFY: a report was edited
Enabled by the ReportsLog system preference
SEARCH_ENGINE
Records changes to mappings
Possible actions
EDIT_MAPPINGS: mappings were modified (edited, deleted)
RESET_MAPPINGS: mappings were reset to the original configuration
SERIAL
Records changes to serial subscriptions
Possible actions
ADD: a new serial subscription was created
DELETE: a serial subscription was deleted
MODIFY: a serial subscription was edited
RENEW: a serial subscription was renewed
Enabled by the SubscriptionLog system preference
SYSTEMPREFERENCE
Records changes to the system preferences
Possible actions
ADD: a new configuration was added
DELETE:
MODIFY: a system preference was edited, a configuration was added (in the case of Automatic item modifications by age for example), records were reindexed
TRANSFERS
Records changes to item transfers between libraries
Possible actions
CREATE: a new transfer was created
UPDATE: a transfer was modified (it was sent, it arrived, or was canceled)
Enabled by the TransfersLog system preference
Parametri di esecuzione
Domanda: C’è modo di filtrare un report SQL personalizzato prima che venga eseguito?
Risposta: Se vuoi rendere il tuo report facile da riusare in differenti situazion, puoi aggiungere parametri a runtime alla tua query. I paramentri a runtime funzionano comne filtri ulteriori sulla query e interverrano prima che vengano mostrati i risultati del report.
Vedi trucchi su come scrivere i parametri runtime dei report.
Ricerca
Ricerca avanzata
Scorri indici
Domanda: Che cosa significa «Scorri indici» sulla pagina di ricerca avanzata?
Risposta: Quando si sceglie un indice, si immette un termine, si spunta «Scorri indici» e si esegue la ricerca, Koha mostra il termine ricercato ed i termini successivi trovati nell’indice, con il numero di record corrispondenti. Ossia, la ricerca non è eseguita direttamente nel catalogo, ma prima nell’indice selezionato; funziona su un solo indice alla volta e solo senza limiti sull’ubicazione (la ricerca avviene su tutte le biblioteche).
Ricerca di termini che iniziano per un carattere specifico
Domanda: Come faccio a cercare tutti i titoli che iniziano per «C»?
Risposta: E” possibile cercare elementi che iniziano per un carattere od una serie di caratteri utilizzando la parola chiave CCL (Common Command Language) «first-in-subfield»
esempio: ti,first-in-subfield=C
Ricerca con caratteri jolly
Domanda: Qual è la differenza tra una ricerca per parole chiave utilizzando «*» (asterisco) rispetto ad una fatta utilizzando «%» (percento)? Funzionano entrambe, ma restituiscono risultati differenti; perché?
Risposta: i caratteri jolly sono «*»,»?»,»%» e «.» (punto). Si possono usare per rappresentare uno o più caratteri all’interno di una parola; Due dei caratteri che possono essere utilizzati nelle ricerche in Koha sono l’asterisco (”*”) ed il simbolo di percentuale (“%”). Il loro comportamento nelle ricerche è però diverso.
L’asterisco * forza una ricerca più precisa dei primi caratteri immessi prima di «*». L’asterisco permette un numero infinito di caratteri nella ricerca, fintanto che i primi caratteri immessi dall’utente rimangono gli stessi. Per esempio, una ricerca per autore utilizzando il termine «Smi*» restituirà una lista di autori che può includere, per esempio, Smith, Smithers, Smithfield, Smiley. Ovviamente il risultato dipende dal contenuto del proprio database.
Il percento tratta le parole immesse dall’utente in termini di «somiglia a». Perciò una ricerca per «Smi%» troverà tutte le parole che «somigliano» a Smi, e questo conduce ad un elenco di risultati molto più vario. Per esempio, i risultati potrebbero comprendere Smothers, Smith, Smelley, Smithfield e molti altri, a seconda del contenuto del proprio database.
In sostanza: il carattere jolly «*» esegue una ricerca più precisa, mentre «%» esegue una ricerca per termini somiglianti.
Ricerca per titolo
Domanda: Perché una ricerca Zebra per titolo che contiene «Help» non restituisce «The help» nella prima pagina di risultati?
Risposta: In generale più termini inserisci, più preciso è il risultato. Koha non usa stopwords, cercare con «il» e «uno» funzionerà. Così cercare «The Help» andrà meglio che usare «Help». Usando anche «Title, phrase» il risultato sarà più preciso visto che la ricerca avverrà per frase, i due termini dovranno essere in sequenza senza alcun termine in mezzo.
Some system preferences are known to affect relevancy ranking negatively. These are QueryAutoTruncate and UseICUStyleQuotes.
Nota: Se più risultati hanno lo stesso valore della rilevanza, come secondo criterio saranno ordinati in base al numero del record bibliografico.
Cancella gli indici di Zebra
Esegui questo comando per il reset degli indici di autorità e bibliografici di Zebra.
$ zebraidx -c /etc/koha/zebradb/zebra-authorities-dom.cfg -g iso2709 -d authorities init
$ zebraidx -c /etc/koha/zebradb/zebra-biblios.cfg -g iso2709 -d biblios init
Se sta usando Koha installato con i package, lancia questi comandi per azzerare le authority e i dati bibliogafici negli indici di Zebra:
$ sudo zebraidx -c /etc/koha/sites/YOURLIBRARY/zebra-authorities-dom.cfg -g iso2709 -d authorities init
$ sudo zebraidx -c /etc/koha/sites/YOURLIBRARY/zebra-biblios.cfg -g iso2709 -d biblios init
Cambia YOURLIBRARY con il nome della tua installazione Koha.
Contenuto arricchito
Amazon
Contenuti Amazon
Domanda: Ho attivato tutte le preferenze di Amazon, ed ho immesso entrambe le chiavi, ma nessuno dei contenuti di Amazon appare nel mio sistema. Come mai?
Risposta: Amazon verifica l’ora impostata sul server di Koha ad ogni richiesta e, se l’orologio del server non è regolato correttamente, la richiesta viene respinta. Per risolvere questo problema, assicurarsi di impostare l’ora di sistema in modo corretto. Non appena fatto ciò, i contenuti di Amazon devono apparire immediatamente.
Su Debian il comando è date -s «2010-06-30 17:21» (con la data ed ora corretti per il proprio fuso orario).
Anche Amazon richiede l’ISBN per mostrare coperte dei libri - assicurati che sia giusto nel record bibliografico. Se hai dei record che non mostrano la coperta, prova a passare all’ISBN 10 o 13 nel primo campo 020a.
Amministrazione del sistema
Bcrypt settings
Question: How do I configure bcrypt_settings in the Koha configuration file?
Answer: You need to generate a key and put it in the koha-conf.xml file.
The following command will generate one:
% htpasswd -bnBC 10 "" password | tr -d ':\n' | sed 's/$2y/$2a/'
Then edit $KOHA_CONF and paste the generated key into <bcrypt_settings>. If that section does not exist, add it before the end of the config section (</config) It should look something like:
<bcrypt_settings>$2a$10$PfdrEBdRcL2MZlEtKueyLegxI6zg735jD07GRnc1bt.N/ZYMvBAB2</bcrypt_settings>
Avvertimento
Do not, under any circumstances, copy the example above in your own configuration! A key is like a password: using one that has been posted online is the opposite of secure. Instead, use the command to generate your own key.
Finally, restart memcached then plack (alias restart_all)
Aprire al pubblico il servizio Z39.50
Domanda: Come posso configurare Zebra per attivare il server Z39.50?
Risposta: Aprire con un editor di testo il file KOHA_CONF. Decommentare la riga publicserver. Per esempio:
<!– <listen id=»publicserver» >tcp:@:9999</listen> –>
diventa:
<listen id=»publicserver» >tcp:@:9999</listen>
Then restart zebasrv and connect on the port specified (9999).
Come si pulisce la tabella delle sessioni?
Domanda: C’è un programma che si possa eseguire periodicamente per cancellare le sessioni scadute dalla tabella “sessions”? Non voglio riportare nei salvataggi quei dati inutili tutte le notti.
Risposta: Si può eseguire il processo pianificato «Pulizia del database».
Oppure, appena prima di eseguire un salvataggio (mysqldump), si può troncare la tabella sessions:
mysql -u<kohauser -p<password <koha-db-name -e 'TRUNCATE TABLE sessions'
Hardware
Lettori di codici a barre
Domanda: Quali lettori di codici a barre sono stati provati e funzionano con Koha?
Risposta: Una semplice regola empirica è: «si comporta come una tastiera?» Se la risposta è sì, funziona. In altre parole: se si prende il lettore, si «spara» un codice e la lettura appare in un editor di testo, il lettore è compatibile con Koha.
I punti principali da controllare sono che il lettore si possa collegare opportunamente al computer (su una porta USB o sulla porta tastiera con un cavo ad Y - utile su computer vecchi) e che sia in grado di leggere il tipo di codice a barre in uso.
E” una buona idea provare a leggere alcuni codici «usati», se disponibili, in modo da controllare se il lettore è in grado di leggere correttamente codici sbiaditi, graffiati o stropicciati. Molti lettori sono in grado di leggere numerosi tipi di codice a barre: ce ne sono tanti, e l’elenco delle caratteristiche tecniche dovebbe specificare auali tipi il lettroe è in grado di comprendere. Potrebbe essere necessario regolare qualche impostazione, come i caratteri di prefisso e di suffisso, se si desidera che il lettore mandi un carattere di INVIO a fine lettura, oppure no.
Un ultimo consiglio: alcuni lettori si possono impostare in modalità «sempre accesso» e possono essere forniti con un supporto; altri hanno un grilletto sull’impugnatura, alcuni altri hanno un pulsante sulla parte superiore, altri ancora si tengono come una penna. Pensate al personale che dovrà lavorare con l’apparecchiatura, prima di sceglierne una, perché un pulsante nella posizione sbagliata può essere veramente scomodo da usare.
Stampanti
Stampanti utilizzati da biblioteche Koha
Regola generale in questo caso è che se il tuo browser lo stampa, allora funzionerà su Koha.
Stampante per scontrini POS-X
Sampante Star Micronic (modello preciso ignoto) con driver generico/solo testo.
Star SP2000 (Nelsonville)
Star TSP-100 futurePRINT (Geauga)
«So che ci sono state moltissime domande sulle stampanti per scontrini, così ho pensato di riferire le mie scoperte. Stavamo provando la Star TSP-100 futurePRINT. Ho scoperto che questa stampante è MOLTO facile da configurare per Koha; sono perfino riuscito a personalizzare il job di stampa, aggiungendo il nostro logo (una gif) nella parte alta dello scontrino. Inoltre, con una bitmap disegnata con Paint, sono stato in grado di aggiungere un messaggio nella parte inferiore della ricevuta, che contie le informazioni di contatto, l’orario di apertura ed il sito della biblioteca presso cui il materiale è stato preso in prestito. «
Stampante per scontrini su carta termica Epson TM 88 IIIP
Epson TM-T88IV
Stampare etichette 1x1 con la Dymolabelwriter
Compatibilità con il sistema Braille
Domanda: Esistono tavolette o stampanti Braille che abbiano un convertitore Braille incorporato e che siano compatibili con l’ambiente UNIX?
Answer: You may want to look into BRLTTY [https://brltty.app/].